
Zuletzt aktualisiert am: 12. November 2025
Kundenorientierung im Industrieversicherungssegment bedeutet: Versicherer und Makler müssen ihre Fähigkeiten ausbauen, in digitalen Produkten und Prozessen zu denken. Einfach nur ein neues Kundenportal online zu stellen darf nicht (mehr) im Zentrum der Digitalisierungsstrategie stehen.
Datenmodelle bilden die Basis für das zukünftige Geschäft in der Industrieversicherung. Denn Daten müssen in der heterogenen – und zukünftig digitalen! – Partnerlandschaft von Industriekunden, Maklern, Versicherern, Assekuradeuren, Sachverständigen und vielen anderen möglichst schnell und flexibel fließen können – auch zwischen internationalen Partnern.
Drei Thesen
- Ohne Datenmodelle kann es keine digitalen Produkte geben.
- Ohne digitale Produkte ist keine Prozessautomatisierung möglich.
- Datenmodelle sind damit ein essentieller Baustein für die digitale Kollaboration.
Ein Datenmodell stellt in der Versicherungswirtschaft eine Art gemeinsames Vokabular zwischen den Marktpartnern dar. Je standardisierter die Datenmodelle zwischen Partnern sind, desto einfacher und akkurater läuft ein Datenaustausch. Und dennoch muss jeder Marktpartner eigene Datenmodelle für die Informationen, die im Rahmen des jeweiligen Geschäftsprozesses zu einem Produkt relevant sind, bestimmen und modellieren können. Dies liegt an den unterschiedlichen Interessen, die mit den erfassten Daten verfolgt werden.
Datenmodelle stellen Versicherungswirklichkeit dar
Eine Kurzdefinition könnte lauten: Das Datenmodell beschreibt Daten für einen Anwendungsbereich und ihre Beziehung zueinander. Das macht ein Modell zu einer vereinfachten Darstellung der Wirklichkeit. Grundsätzlich werden Datenmodelle mithilfe von Datenfeldern beschrieben. In Bezug auf ein zu erstellendes Versicherungsangebot können in einem Datenmodell beispielsweise die notwendigen Daten für die Risikobeschreibung und dessen Bewertung, wie Namen und Anschriften von Versicherungsnehmern, die Fläche von Lagerflächen oder auch Ja/Nein-Felder in Risikofragebögen erfasst werden.
So lassen sich diese Datenmodelle fachlich nutzen, um beispielsweise Geschäftsprozesse, Organisationseinheiten und Services zu beschreiben. Technisch werden sie für die Entwicklung von Apps, Plattformen und Webservices genutzt
Der Mehrwert der Datenmodelle liegt in der universellen Verwendung über die Wertschöpfungsketten der nächsten 5, 10, 15 oder sogar mehr Jahre. Sind sie am Anfang einmal richtig konzipiert, lassen sie sich je nach technischer Lösung und Rahmen sehr flexibel weiterentwickeln. Mindestens aber sind Datenmodelle der Startpunkt, um IT-Anwendungen für das Underwriting und die Abwicklung kompromisslos von den Produkten und Prozessen her (neu) zu denken, statt vorhandene Programme mit viel Aufwand laufend anzupassen.
Dafür braucht es jedoch ein auf Relevanz gebautes Datenmodell. Das heißt: Auf eine gute Strukturierung kommt es an. Strukturen helfen bei der langfristigen Wiederverwendbarkeit und Auswertung von Daten.
Drei Praxistipps: Kleiner Start, Konzept und Verprobung
Praxistipp 1: Kleine Datenmodelle statt Monolithen
Entlang eines Geschäftsprozesses kann es viele, kleinere Datenmodelle geben. Statt eines großen Datenmodells für allgemeine Risikodaten, empfiehlt sich die Definition verschiedener Datenmodelle für beispielsweise jeweils die Finanzzahlen und die Tätigkeitsbeschreibung des Kunden. Ebenso könnte man die deckungsrelevanten Daten in Datenmodelle für je die Kasko- und die Haftpflichtdeckung bei Transportversicherungen aufteilen. Gleiches gilt für die Vielzahl der Daten zum Angebotsrahmen, wie Gültig-bis-Datum oder Angebotsnummer, in Abgrenzung zu Daten zum Vertragsrahmen, wie Beginn, Ablauf oder Vertragsnummer, sowie der jeweiligen Deckungsdaten.
Bei einer solchen Strukturierung ist außerdem auf die Historisierung von Datenversionen zu achten. Finanzzahlen kommen beispielsweise aus dem Geschäftsbericht des Versicherungsnehmers: Eine Versionierung je Geschäftsjahr ist also ausreichend. Deckungsrelevante Daten können sich aufgrund von unterjährigen Nachträgen dagegen mehrfach im Versicherungsjahr ändern. Daher ist für die Prämienberechnung oder die Schadenbearbeitung eine entsprechende Historisierung je Änderungsdatum unabdingbar. Diese Unterschiede in der Historisierung liefern wichtige Anhaltspunkte für geeignete Schnitte des Datenmodells.
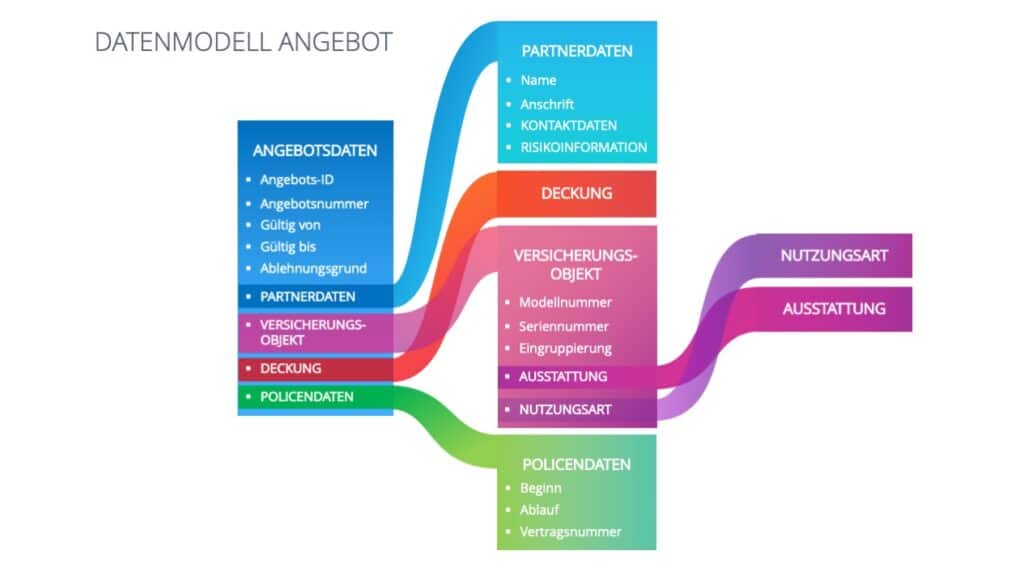
Ausschnitt eines Datenmodells für ein Angebot
Praxistipp 2: Strukturierungsansatz und Mut zur Unschärfe
Nehmen wir ein Datenmodell zur Abbildung aller wichtigen Daten einer D&O-Deckung als Entität. Was sind aber wichtige Daten? Das kann am besten entscheiden, wer den Zweck der Datenerfassung und -verarbeitung im Auge behält. Das EVA-Prinzip ist ein uralter, aber effektiver Ansatz, um diese Frage zu beantworten: Von der Eingabe über die Verarbeitung zur Ausgabe. Das Ziel der Datenverarbeitung im Beispiel ist das Erstellen eines Angebots für die D&O-Versicherung. Vom Ende gedacht lassen sich die benötigten Daten so effizient und pragmatisch für die Deckung strukturieren. Grundsätzlich bietet sich eine Strukturierung nach Entität oder Prozess, beziehungsweise Prozessschritt an.
Unabhängig vom Vorgehen birgt jeder Ansatz eine Herausforderung, die manchmal in der konkreten Ausarbeitung zur Schwierigkeit werden kann: Sie erfordert Pragmatismus in der Definition und den Mut zur Unschärfe oder auch Unvollständigkeit. Dieser Erarbeitungsprozess ist zugleich eine gute Gelegenheit, Komplexität in Datenfeldern und Bedingungen zu reduzieren.
Praxistipp 3: Frühes Verproben der fachlichen Logik deckt Lücken auf
Theorie und Praxis lassen sich gut verproben, wenn ein Datenmodell direkt in der Anwendung erlebbar wird. Auf Basis des sogenannten Low Code-Ansatzes lassen sich Datenfelder direkt von Fachexpert*innen modellieren und in der technischen Anwendung zeigen. Die logische Modellierung dahinter lässt sich leicht erlernen, Programmierkenntnisse sind nicht notwendig. So ist es möglich, dass Fachexpert*innen im Workshop direkt ein Datenmodell auf Basis echter Testdaten erproben können. Fachbereichsleiter*innen können das Datenmodell direkt in der Anwendung sehen, Lücken identifizieren und besser entscheiden. Ob mit oder ohne Low Code sollte der technische IT-Rahmen so genügend Flexibilität für zukünftige Änderungen und Weiterentwicklung bieten.
Intensive Kollaboration von Fachbereich & IT führen zum Ziel
Unabhängig davon wie konkret Datenmodelle entwickelt werden, gibt es eine essentielle Grundvoraussetzung: Datenmodelle zu definieren ist keine reine IT-Aufgabe, diese Aufgabe betrifft Fachbereiche mindestens genauso. Ein Höchstmaß an Kommunikation sowie Wissen und Verständnis zwischen Technik und Fachbereichen sind dafür nötig. Datenmodelle überdauern die Lebensdauer von Prozessen und sollten sorgfältig aufgebaut werden. Dafür ist ein gemeinsamer Kompetenzaufbau die Voraussetzung. Das zeigt: Die grundlegende Einführung von Datenmodellen für zukünftige Geschäfte kann nur mit einem parallelen Change-Prozess funktionieren.
Dass sich Datenmodelle und der sehr aufwändige Prozess lohnen, zeigt das Beispiel des Hamburger Industriemaklers Gossler, Gobert & Wolters (GGW). Rebecca Stodt, bei GGW verantwortlich für Digitalisierung fasst zusammen: „Nach anfänglichen Widerständen und dem später erfolgreich abgeschlossenen Projekt kommen nun Nachrichten aus den Fachbereichen, dass die Arbeit mit den jetzt gut strukturierten Daten Spaß macht und die Auswertungen funktionieren.“ Außerdem ist eine ihrer Erkenntnisse: Die Datenmodellierung sollte höher priorisiert sein als die Prozessmodellierung, weil saubere Daten das A und O sind.
Welche Erfahrungen bei GGW bislang mit der Digitalisierung auf Basis von Datenmodellen gemacht wurde und wie sie aktuell arbeiten, hat Rebecca Stodt im Podcast “Industrieversicherung Digital” kürzlich ausführlich erzählt.
Bildquelle: Shutterstock
Versicherungsforen-Themendossier
Dieser Text ist zuerst im Themendossier 3/2021 der Versicherungsforen Leipzig erschienen. Den Artikel gibt es als Download hier.





