
Last Updated on 12. November 2025
Customer orientation in the industrial insurance segment means: insurers and brokers must develop their ability to think in terms of digital products and processes. Simply putting a new customer portal online must not be the focus of the digitalisation strategy (anymore).
Data models form the basis for future business in industrial insurance. In the heterogeneous – and in future digital! – partner landscape of industrial customers, brokers, insurers, underwriters, experts and many others, data must be able to flow as quickly and flexibly as possible - even between international partners.
Three theses
- Without data models, there can be no digital products.
- Without digital products, process automation is not possible.
- Data models are therefore an essential building block for digital collaboration.
In the insurance industry, a data model represents a kind of common vocabulary between the market partners. The more standardised the data models between partners are, the easier and more accurate the data exchange will be. And yet each market partner must be able to determine and model its own data models for the information that is relevant to a product in the context of the respective business process. This is due to the different interests that are pursued with the collected data.
Data models represent insurance reality
A short definition could be: The data model describes data for an application area and their relationship to each other. This makes a model a simplified representation of reality. Basically, data models are described with the help of data fields. In relation to an insurance offer to be created, for example, the necessary data for the risk description and its evaluation, such as names and addresses of policyholders, the area of storage space or yes/no fields in risk questionnaires can be recorded in a data model.
These data models can be used professionally, for example, to describe business processes, organisational units and services. Technically, they are used for the development of apps, platforms and web services.
The added value of data models lies in their universal use across the value chains of the next 5, 10, 15 or even more years. Once they have been designed at the beginning, they can be further developed very flexibly depending on the technical solution and framework. At the very least, however, data models are the starting point for (re)thinking IT applications for underwriting and life cycle from the product and process perspective without compromise, instead of constantly adapting existing programmes at great expense.
However, this requires a data model built on relevance. This means that good structuring is important. Structures help with the long-term reusability and evaluation of data.
Three practical tips: Small start, concept and trial
Practical tip 1: Small data models instead of monoliths
There can be many, smaller data models along a business process.
Instead of one big data model for general risk data, it is recommended to define different data models for, for example, the financial figures and the description of business operation of the client. Likewise, one could use the coverage related data and structure them into separate models for each the Kasko- and Haftpflichtdeckung for transportation insurance. The same applies to the large amount of data on the scope of the offer, such as valid-to date or offer number, in distinction to data on the contract framework, such as start date, expiry date or contract number, as well as the respective coverage data.
In such a structuring, attention must also be paid to the historisation of data versions. Financial figures, for example, come from the policyholder’s annual report: one version per financial year is therefore sufficient. Coverage-relevant data, on the other hand, can change several times in the insurance year due to endorsements during the year. Therefore, a corresponding historicisation per change date is indispensable for premium calculation or claims processing. These differences in historisation provide important clues for suitable cuts of the data model.
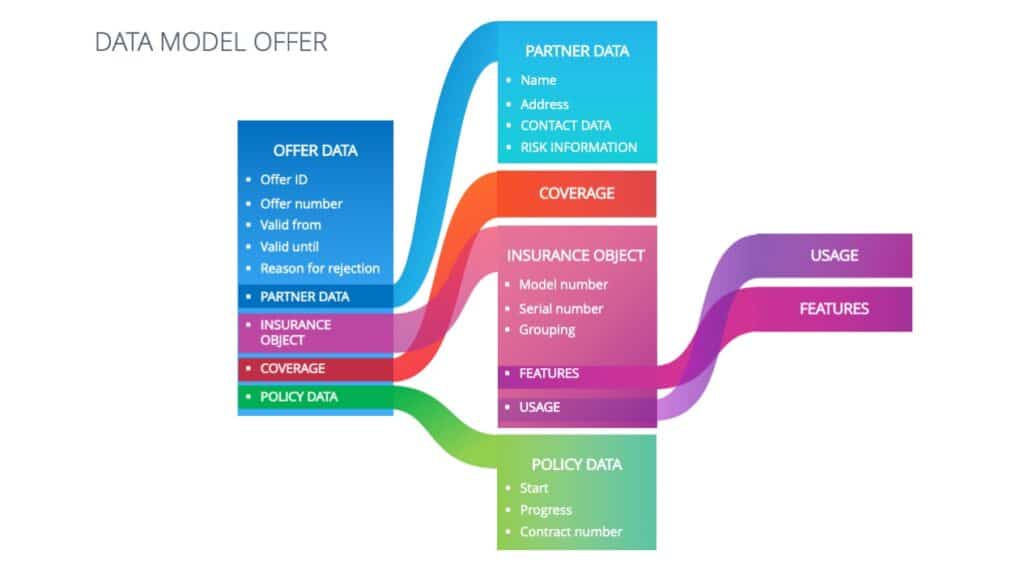
Section of a data model for an offer
Practical tip 2: Structuring approach and courage to be vague
Let’s take a data model to represent all important data of a D&O cover as an entity. But what is important data? The best way to decide that is to keep in mind the purpose of collecting and processing the data. The IPO principle is an age-old but effective approach to answering this question: from input to processing to output. The goal of the data processing in the example is to create a quotation for D&O insurance. Hence, the required data can be structured efficiently and pragmatically for coverage when this output is used as a structuring guide. Basically, structuring according to entity or process, or process step, is a good idea.
Regardless of the procedure, every approach holds a challenge that can sometimes become a difficulty in the concrete elaboration: It requires pragmatism in the definition and the courage to be vague or incomplete. This process is also a good opportunity to reduce complexity in data fields and conditions.
Practical tip 3: Early testing of business logic reveals gaps
Theory and practice can be tested well when a data model can be experienced directly in the application. Based on the so-called low-code approach, data fields can be modelled directly by business experts and demonstrated in the technical application. The logical modelling behind this is easy to learn, programming knowledge is not necessary. This makes it possible for subject matter experts to directly test a data model on the basis of real test data in the workshop. Heads of department can see the data model directly in the application, identify gaps and make better decisions. Whether with or without low code, the technical IT framework should offer sufficient flexibility for future changes and further development.
Intensive collaboration between business departments & IT leads the way
Regardless of how data models are developed, there is one essential prerequisite: Defining data models is not a purely IT task; this task affects the business departments at least as much. A high degree of communication as well as knowledge and understanding between technology and business departments is necessary. Data models outlast the lifetime of processes and should be built carefully. The prerequisite for this is the joint development of competences. This shows: The fundamental introduction of data models for future business can only work with a parallel change process.
The example of the Hamburg-based industrial broker Gossler, Gobert & Wolters (GGW) shows that data models and the very complex process are worthwhile. Rebecca Stodt, responsible for digitalisation at GGW, summarises: “After initial resistance and the later successfully completed project, news is now coming from the departments that working with the now well-structured data is fun and the evaluations work.” Moreover, one of their findings is: Data modelling should be prioritised higher than process modelling because clean data is the be-all and end-all.
Rebecca Stodt recently shared details in the podcast “Industrieversicherung Digital” what experiences GGW has had with digitisation based on data models and how they are currently working.




