
Zuletzt aktualisiert am: 7. November 2025
Unternehmen stehen bei der Einführung von generativer KI in der Softwareentwicklung vor einem Zielkonflikt: Schnelle Integration moderner LLMs in Produkte auf der einen Seite – und Datenschutz, Compliance, Auditierbarkeit sowie klare Zuständigkeiten auf der anderen.
In der Praxis haben sich drei Betriebsmodelle für KI-Workloads etabliert:
1. Public API
2. Cloud im eigenen Tenant
3. On-Premise
Diese drei Wege unterscheiden sich in Datenschutz-Niveau, Skalierbarkeit und Integrationsaufwand, lassen sich aber durch API-Gateways und Agent-Orchestrierung zu einer hybriden, sicheren Enterprise-KI-Architektur verbinden.
Public API – Schnelligkeit und Innovation
Public APIs sind der schnellste Einstieg in generative KI. Innerhalb weniger Stunden lassen sich Chatbots, Assistenten oder Analyse-Tools aufsetzen – ideal für nicht-sensible Daten.
Vorteile einer Public API
- Extrem kurze Time-to-Value
- Sofortiger Zugriff auf neue Modellfähigkeiten
- Skalierung und Kosten zunächst beim Provider
Grenzen einer Public API
- Eingeschränkte Datenhoheit
- Fehlende Auditierbarkeit
- Nicht geeignet für sensible Informationen
Typische Use Cases: Prototyping, Content-Generierung, Data-Exploration, öffentlich zugängliche Informationen
Cloud im eigenen Tenant – Skalierung und Integration
Der Betrieb in der Cloud erweitert den reinen Modellaufruf zu einem vollständigen Enterprise-Workload. Neben elastischer Compute-Kapazität (inkl. GPUs) bietet die Cloud ein breites AI-Ökosystem: Identitäts- und Rechtemanagement (RBAC), CI/CD, Observability, Vektor-Datenbanken und spezialisierte Services wie OCR, Speech-to-Text, Vision oder AI Foundry-Angebote.
Vorteile einer Cloud im eigenen Tenant
- Integrierte Governance und Compliance
- Standardisierte Bereitstellung via Infrastructure as Code (IaC)
- EU-konforme Datenresidenz (je nach Provider)
Herausforderungen einer Cloud im eigenen Tenant
- Provider-Lock-in durch IAM oder Storage-APIs
- FinOps-Management bei Dauerlast notwendig
Typische Use Cases: Produktive interne KI-Workflows, Retrieval-Augmented-Generation (RAG), Geschäftsprozess-Automatisierung
On‑Premise – maximale Kontrolle und Datenhoheit
On-Premise-Betrieb bietet vollständige Kontrolle über Daten, Infrastruktur und Modellversionen – ein Muss für stark regulierte Branchen oder sensible Daten.
Vorteile von On-Premise
- Höchste Datenhoheit und Sicherheit
- Lokale Optimierung (z. B. Quantisierung, Distillation)
- Auditierbarkeit auf Stack-Ebene
Nachteile von On-Premise
- Hoher Betriebs- und Wartungsaufwand
- Fehlende Cloud-Services (OCR, ASR, Guardrails etc.) – mit entsprechender Expertise und erheblichem Aufwand lässt sich dies zwar mitigieren, ist aber keinesfalls einfach.
- Wirtschaftlich nur sinnvoll bei dauerhaft hoher Auslastung
Typische Use Cases: Regulatorische Domänen, Finanz-/Gesundheitswesen, interne AI-Evaluation
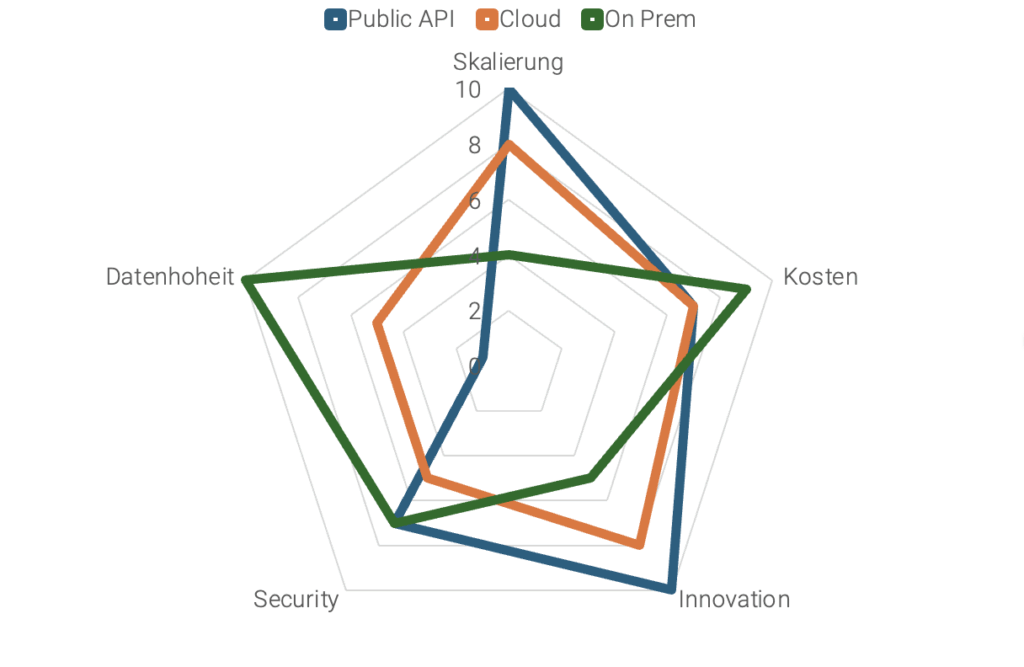
Vergleich der drei KI-Betriebsmodelle
| Kriterium | Public API | Cloud (eigener Tenant) | On-Premise |
| Time-to-Value | sehr schnell | schnell (IaC, Automatisierung) | langsam (Setup) |
| Datenhoheit | gering | mittel bis hoch | maximal |
| Kostenmodell | Opex, günstig zum Start | Opex, elastisch | CapEx + Opex, bei Auslastung gut |
| Lock-in-Risiko | hoch | mittel (reduzierbar via IaC) | gering (technisch) |
| Governance & Audit | eingeschränkt | integriert | vollständig |
| Einsatzfelder | PoC, öffentliche Daten | produktive KI-Workflows | hochsensible Bereiche |
API‑Gateway als KI-Integrationsschicht
Die drei Wege sind nicht exklusiv – im Gegenteil: Ein API- oder Model-Gateway fungiert als einheitliche Schnittstelle zwischen Anwendungen und KI-Modellen. Es sorgt für Policy-Enforcement, Logging, RBAC, Rate-Limits und Routing-Entscheidungen auf Basis von:
- Datenklassifizierung
- Latenzbedarf
- Kosten und Sensitivität
So kann derselbe Use-Case flexibel über Public API, Cloud oder On-Prem laufen, ohne dass Fachanwendungen angepasst werden müssen.
Ergebnis: saubere Audit-Trails, belastbare Observability/FinOps-Metriken bis auf Routen-Ebene und technologische Unabhängigkeit
Agent‑Orchestrierung – von Prompts zu Prozessen
Mit Agent-Orchestrierung wird KI-Nutzung von Einzelprompts zu skalierbaren, reproduzierbaren Geschäftsprozessen. In Orchestrierungstools oder gleichwertigen internen Pipelines werden die Aufgaben (z. B. Dokumenteneingang → OCR → Klassifizierung → Generierung → Prüfung) in kontrollierbare Schritte zerlegt und mit Kontrollpunkten verbunden. Über das Gateway lässt sich jeder Schritt abhängig von Sensitivität, Jurisdiktion und Zweckbindung dynamisch routen.
Ein Beispiel: Vertragsdokumente werden zunächst in einem EU-Cloud-Service erfasst und per OCR sowie NLP-Parsing in strukturierte Abschnitte zerlegt; die anschließende Extraktion und Bewertung sensibler Passagen, etwa personenbezogener Daten oder Klauselvarianten, erfolgt in der On-Prem-Umgebung. Nach Abschluss der internen Prüfung werden die anonymisierten Metadaten an ein Cloud-LLM übergeben, das eine Zusammenfassung, Risikoeinstufung oder Handlungsempfehlung generiert. Alle Verarbeitungsschritte sind im Gateway registriert, inklusive Routing-Entscheidung, Modellversion und Audit-Trail. Policies garantieren, dass Originaldokumente die kontrollierte Zone zu keinem Zeitpunkt verlassen. Das ermöglicht Sensitivity-aware Routing und Policy-konformes Prompting über mehrere Umgebungen hinweg.
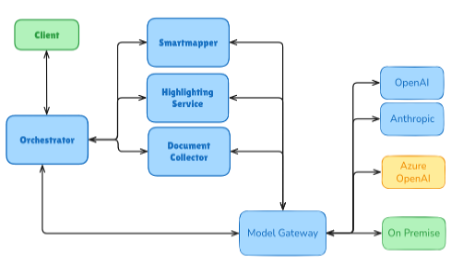
Integration in Enterprise‑AI‑Workflows
Ein typischer Flow beginnt am Orchestrator, der sehr schnell mit dem Gateway kommuniziert, wo Policy-Checks, Secrets-Management und Observability greifen. Anschließend leitet die Routing-Logik an Public API, Cloud oder On-Prem weiter; Antwort, Kosten, p95-Latenz und Entscheidungsweg werden zentral im Audit- und Observability-Stack erfasst.
Für RAG-Szenarien ergänzen Retriever, Vektor-DB und Kontextaufbau die Pipeline – wahlweise als Cloud-Service oder on-prem im eigenen Stack. Über CI/CD und IaC werden Gateway-Konfigurationen, Prompts, Modelle und Pipelines versioniert ausgerollt; Canary-Vergleiche zwischen Modellvarianten ermöglichen laufende Optimierung von Qualität, Kosten und Latenz.
Governance ist Teil der Architektur, nicht Add-on: Policies, RBAC, PII-Schutz und Audit-Mechanismen sind von Beginn an integriert.
Beispiel: Ein interner Wissens-Assistent verarbeitet Support-Anfragen über das zentrale API-Gateway. Dort greifen zunächst Policy-Checks und Secrets-Management, bevor die Anfrage anhand ihrer Sensitivität in eine Cloud-Instanz mit RAG-Pipeline geroutet wird. Retriever und Vektor-Datenbank stellen kontextrelevante Dokumente bereit, das LLM erzeugt eine Antwort, und sämtliche Metriken – inklusive Tokenverbrauch, p95-Latenz und Modell-Routing – werden im Observability-Stack protokolliert. Das Gateway führt den vollständigen Audit-Trail; Konfiguration, Prompts und Modellversionen werden versioniert über CI/CD-Pipelines ausgerollt. Policies und RBAC sichern, dass jeder Schritt nachvollziehbar und regelkonform abläuft.
Fazit: Hybride Enterprise-KI als Schlüssel zur Enterprise-Reife
- Public API liefert maximale Geschwindigkeit.
- Cloud skaliert produktionsreif mit einem breiten AI-Ökosystem.
- On-Premise schafft Vertrauen durch maximale Kontrolle.
Die Kombination dieser Ansätze über API-Gateways und Agent-Orchestrierung ermöglicht es, je nach Use-Case und Schritt das richtige Datenschutz- und Performance-Niveau zu wählen. So entsteht eine skalierbare, konforme und provider-unabhängige Enterprise-AI-Architektur.
FAQ: Enterprise-AI-Architekturen – Public API, Cloud und On-Prem
Was sind die drei typischen Betriebsmodelle für Enterprise-KI?
Die drei zentralen Betriebsmodelle für Enterprise-KI sind Public API, Cloud im eigenen Tenant und On-Premise. Sie unterscheiden sich vor allem in Datenschutz, Governance, Skalierbarkeit und Kostenstruktur. In der Praxis werden sie oft hybrid kombiniert, um je nach Datenklassifizierung oder Use-Case das passende Niveau an Kontrolle und Geschwindigkeit zu erreichen.
Wann ist der Einsatz einer Public-API-Lösung sinnvoll?
Public APIs eignen sich für schnelle Experimente und Prototypen mit generativer KI. Unternehmen können neue Modelle oder Use-Cases innerhalb weniger Stunden testen. Allerdings ist die Datenhoheit eingeschränkt, weshalb sich Public APIs nur für nicht-sensible Informationen oder offene Datensätze eignen.
Welche Vorteile bietet eine Cloud-Instanz im eigenen Tenant?
Ein eigener Cloud-Tenant ermöglicht die Kombination aus Skalierbarkeit und Governance. Unternehmen behalten Kontrolle über Identitäten, Policies und Datenresidenz, während sie gleichzeitig auf gemanagte AI-Services wie Vektor-Datenbanken, CI/CD, Secrets-Management oder Monitoring zugreifen können. Dieses Modell ist ideal für produktive KI-Workflows und Retrieval-Augmented-Generation (RAG).
Warum setzen regulierte Unternehmen auf On-Premise-AI?
On-Premise bietet maximale Datenhoheit und Auditierbarkeit, da alle Daten, Modelle und Logs innerhalb der eigenen Infrastruktur bleiben. Das ist entscheidend für regulierte Branchen wie Finanzwesen, öffentliche Verwaltung oder Gesundheit. Nachteilig sind höherer Wartungsaufwand und der Wegfall vieler Cloud-Komfortfunktionen – dafür entsteht vollständige Kontrolle und Nachvollziehbarkeit.
Welche Rolle spielt ein API-Gateway in der KI-Architektur?
Ein API- oder Model-Gateway fungiert als zentrale Schicht zwischen Anwendungen und verschiedenen KI-Backends. Es steuert Routing, Policy-Checks, Secrets-Management, RBAC und Observability. Dadurch kann je nach Datenklassifizierung oder Sensitivität automatisch entschieden werden, ob ein Request an eine Public API, Cloud oder On-Prem-Instanz geht – ohne dass Applikationen angepasst werden müssen. Das verbessert Governance, Transparenz und Kostenkontrolle (FinOps).
Was bedeutet Agent-Orchestrierung in Enterprise-KI?
Agent-Orchestrierung beschreibt das Steuern mehrstufiger KI-Prozesse anstelle einzelner Prompts. Ein Workflow kann z. B. Dokumenteneingang, Klassifizierung, Retrieval, Generierung und Prüfung enthalten. Das Gateway bleibt im Loop, überwacht den Ablauf, erzwingt Policies und wählt das jeweils geeignete Backend. So entstehen nachvollziehbare, reproduzierbare Enterprise-AI-Flows statt isolierter Modellaufrufe.
Wie wird Governance in Enterprise-AI-Workflows sichergestellt?
Governance ist Teil der Architektur – nicht Add-on. Policies, Role-Based Access Control (RBAC), PII-Schutz und Audit-Trails sind integriert in Gateway, Orchestrierung und CI/CD. Jede Modellentscheidung, Latenz, Kostenmetrik oder Routing-Entscheidung wird im Observability-Stack protokolliert. So entsteht Compliance-by-Design, nicht nachträgliche Kontrolle.
Was versteht man unter einem typischen Enterprise-AI-Flow?
Ein Enterprise-AI-Workflow beginnt meist am Gateway:
– Policy-Checks und Secrets-Handling
– Routing zu Cloud, On-Prem oder API
– Messung von Antwortzeit, Kosten und Modellpfad
– Speicherung im Audit-Stack
Für RAG-Szenarien kommen Retriever, Vektor-DB und Kontextaufbau hinzu.
Deployments erfolgen versioniert über CI/CD und Infrastructure as Code (IaC), um Modelle, Prompts und Pipelines konsistent zu verwalten.
Wie lassen sich Qualität, Kosten und Latenz kontinuierlich optimieren?
Über Canary-Vergleiche werden Modellversionen oder Gateway-Konfigurationen parallel getestet. Metriken wie Tokenverbrauch, p95-Latenz und Antwortqualität fließen in das zentrale Monitoring. Auf dieser Basis lassen sich Qualität, Performance und Kosten laufend ausbalancieren – ein wichtiger Bestandteil des FinOps-Frameworks für Enterprise-AI.
Warum ist eine hybride Architektur oft die beste Wahl?
Eine hybride Enterprise-AI-Architektur kombiniert die Flexibilität der Cloud, die Geschwindigkeit von Public APIs und die Sicherheit von On-Premise. Über Gateways und Orchestrierung kann für jeden Verarbeitungsschritt dynamisch entschieden werden, wo Daten verarbeitet werden dürfen. So entsteht eine skalierbare, konforme und providerunabhängige KI-Landschaft, die Geschwindigkeit und Governance vereint.




