
Last Updated on 13. September 2023
The more extensive and complex forms in an application become, the more hopeless it is to provide test data manually. mgm has therefore developed a procedure that generates test data completely automatically for the quality assurance of enterprise software during development. The mgm A12 Test Data Generator (TDG) generates technical test data fully automatically based on domain-oriented models and detects contradictions in the rules “along the way”.
Short & concise
- Valid test data is required for testing complex business applications. This test data can only be generated manually with a great deal of effort.
- The mgm A12 test data generator translates the validation and calculation rules underlying the fields of an A12 form into mathematical equation systems, solves them, and thus generates valid test data.
- Test data generation is fully automated and covers 100 percent of all fields in the models. No expert knowledge of the content of the forms is required.
- The mgm A12 test data generator also detects inconsistencies in the rules and generates a detailed report to help the user understand and resolve the inconsistencies. This feature is already integrated into the modeling tools of the model-based A12 Enterprise Low Code Platform.
In order to test complex business applications automatically or manually, technically correct test data is required. This is particularly complicated because complex business applications usually contain complex business rules. These rules define which values are allowed in the data and thus serve as guidelines for generating the test data. Normally, the manual creation and maintenance of such test data requires the deployment of large teams of domain experts, which involves considerable effort.
During the development of mgm’s A12 low-code platform, it was therefore clear at an early stage that a generic solution was required to handle these tasks and generate test data automatically without relying on specialist knowledge. Since the subject matter of an A12 application is represented in models, the models can be used as the basis for this automated test data generation. However, automatically generating test data for model-based forms is not an easy task, as validation rules complicate the process considerably.
One possible approach is to use a brute force approach. Here, we generate random test data and then check its validity. The validation rules thereby limit the set of possible solutions. However, the probability of finding a valid record decreases exponentially with the number of fields and rules. We found that even for a small form with 100 fields and 100 rules, it would take a computer several days to generate a single valid record with a probability of 50 percent. Even for medium-sized forms, the required computing time would be even longer than the age of the universe since the Big Bang.
In the labyrinth of possibilities: Contradictions and right turns
This is why it is crucial to analyze validation rules when generating test data. In A12, these rules are formulated in the powerful A12 rule language. But here the next problem appears: Most rules consist of multiple subconditions linked by “Or”. This means there are several ways not to violate them. If you want to generate test data automatically, you have to decide for each rule which option to choose. Each of these decisions is like a fork in a complex maze. The size of this maze grows exponentially with the number of “or” links. Even with medium-sized forms, this maze becomes practically infinite in size. In addition, most of the branches in this maze lead to dead ends. For this reason, finding a way through this almost infinite labyrinth is extremely challenging.
Finding a way out of the labyrinth: the SMT solver
Fortunately, there are special algorithms that are specialized for exactly such problems. They address the questions
- in which order decisions should be made
- how to quickly find out which turn is a dead end, and
- how to utilize earlier findings in the case of additional conditions and to which branches one has to go back.
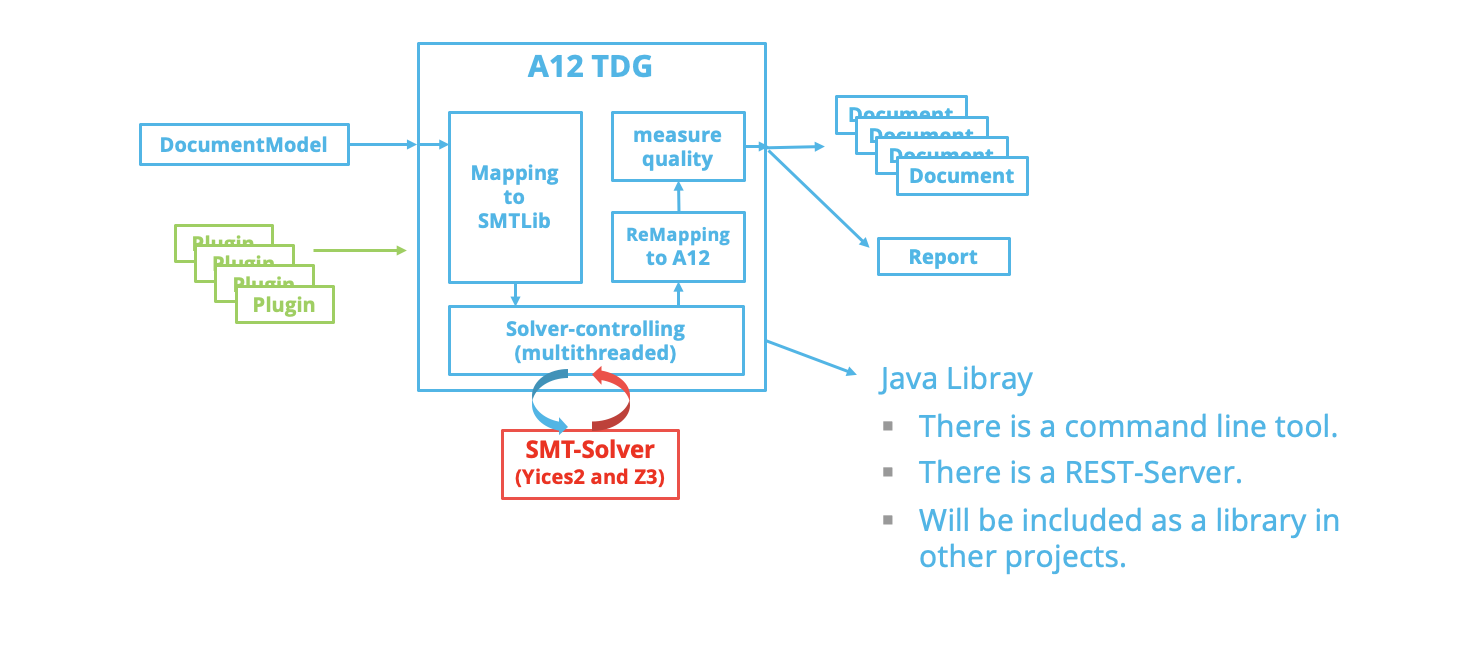
In computer science and mathematics, these algorithms belong to the field of so-called “satisfiability modulo theories” (SMT). They deal with decision problems that involve the solvability of logical formulas. For practical use, there are special SMT solvers that provide the algorithms in libraries. And there is the standardized language SMT-LIB to communicate with the SMT solvers.
To be able to use an SMT solver for test data generation of applications developed with the A12 platform, the mgm A12 Test Data Generator translates the domain-specific rules from the A12 rule language into SMT-LIB. The result is a system of equations that is solved by the SMT solver. The solution is translated back into an A12 data set.
Example of translation from A12 to SMT-LIB
Suppose that in an A12 model there are DateField1 and DateField2 fields. And it is a requirement that DateField2 always contains a later date than DateField1. Then a validation rule is defined in the A12 model to ensure this. This rule always describes the case of an error. In this case, an error occurs if both DateField1 and DateField2 are specified and the value in DateField1 is greater than or equal to the value in DateField2.
The corresponding validation rule in the A12 rule language is:
[DateField1] >= [DateField2].In the mgm A12 Test Data Generator, DateField1 is translated into four variables: There is the boolean variable DateField1-B, which takes the value true if the field is specified. Further there are the integer variables DateField1-y, DateField1-m and DateField1-d for year, month and day. The translation of DateField2 is done in an analogous way.
Our validation rule in SMT-LIB looks like this:
(assert
(not
(and
DateField1-B
DateField2-B
(or
(> DateField1-y DateField2-y)
(and
(= DateField1-y DateField2-y)
(> DateField1-m DateField2-m))
(and
(= DateField1-y DateField2-y)
(= DateField1-m DateField2-m)
(>= DateField1-d DateField2-d))))))
In SMT-LIB, the use of operators is done by prefixing notation. In addition, rules are formulated positively, which is why the rule is preceded by not.
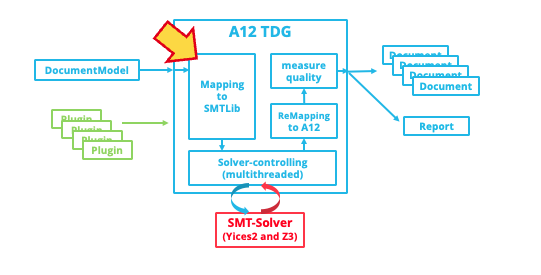
Challenges and successes of translating the A12 rule language into SMT-LIB
However, this process requires a translation of the complete A12 rule language: for each field and for each rule, an equivalent in SMT-LIB is needed. We have been working on this translation in the team of mgm A12 Test Data Generator for years and have tried different translation options again and again. In the meantime, the mgm A12 Test Data Generator covers 100 percent of our productive forms and we continue our efforts to keep up with the development of the A12 rule language.
Performance in the mgm A12 Test Data Generator: A Narrow Path
The second major challenge in the A12 Test Data Generator is the performance of the SMT solvers. There is a risk of exponentially increasing computation time, which highlights the complexity of the problem, as explained earlier. Performance is affected by factors such as the size and complexity of the form, the way the A12 rule language is translated into SMT-LIB, and the general handling of the SMT solver.
Working on performance in the A12 Test Data Generator (TDG) is akin to finding a narrow paved path through a swamp: the slightest misstep can lead to enormous runtime delays. Although SMT solvers continue to improve, test data generation can take hours for large models with complex rule sets. The optimal translation of the A12 control language into SMT-LIB and the best setting and use of the SMT solvers are the result of years of research and continuous improvement. Compared to our early attempts, the current solution requires only a fraction of the original runtime.
As business applications become more complex, so do the models. For this reason, the team of mgm A12 Test Data Generator is continuously investing in performance improvements to keep pace with the increasing complexity of the technicality in the forms.
Solution for nonlinearities in the mgm A12 test data generator
In the test data generator, nonlinearities represent a complex algorithm. When one field is multiplied by another field in a rule, a nonlinearity is created. However, using conventional algorithms in SMT solvers for models with nonlinearities is not practical for our purposes due to their long execution time.
To overcome this problem, we have developed a method in mgm A12 Test Data Generator that eliminates nonlinearities. Here, individual fields are pre-populated with meaningful values before being passed to the SMT solver. The implementation of this procedure is extremely complex, as the preassignment can potentially cause contradictions.
Our initial pre-population algorithm was continuously improved, but eventually reached its limits. In the summer of 2022, we tried a completely new approach that has since been successfully deployed in the production environment and has significantly improved performance and data quality. This new approach allowed us to successfully overcome the challenges of nonlinearities.
Diverse test data for different use cases
The A12 test data generator provides the ability to generate different types of data sets for different use cases. The generated test data varies depending on the requirements:
- Minimal test cases for smoke tests: this test data is used to check basic functionalities and represents minimal inputs to enable quick verification.
High coverage test cases for automated testing: This test data is specifically designed for automated testing and covers a wide range of scenarios to ensure comprehensive application verification. - Negative tests: These test data are created specifically to intentionally violate individual validation rules to identify potential vulnerabilities and errors.
- Test cases with all allowed characters for automated testing: This test data includes all possible allowed characters and is used to check the robustness and reliability of the application.
- Test cases with “nice” test data for manual tests: With this test data, the focus is on generating readable and realistic test data for manual tests to enable user-friendly and practical testing.
By generating this diverse test data, the A12 test data generator can effectively cover various application scenarios.
Efficient identification of rule contradictions in the mgm A12 test data generator: A solution for complex cases
During the development of the test data generator, we identified another challenge that it can effectively handle: the detection of rule contradictions that cause some fields not to be specified.
A simple example: rule 1 states that fields A and B of a form must be specified together. Rule 2 states that fields A and B must not be specified together. As a result, users cannot make entries for the affected fields. They can no longer be used due to the rule contradiction.
In practice, such simple contradictions are immediately noticeable. However, there are much more complex cases that span multiple rules. These are very difficult to detect. In practice, for example, test data generation has uncovered a contradiction that spanned a context of eight rules and eight fields in a tax form. A human has little chance of detecting such errors.
Detecting contradictions during modeling
The process not only detects that such contradictions exist. It also reveals which rules and fields are affected. This information is invaluable for error-free modeling – especially if business analysts and domain experts have access to it as early as possible in the development process.
In the Enterprise AI Low Code Platform A12, this tool is already integrated into the modeling tools. The mgm A12 Test Data Generator points out inconsistencies directly during domain-oriented modeling and ensures that the models are flawless from a mathematical point of view.
This is a nice example of how the results of an internal research project can be second-guessed. Thus, we have not only found the ways out of the labyrinth, but in passing we have also tamed the dragon dwelling in it.




