
Last Updated on 7. November 2025
Companies face a fundamental trade-off when introducing generative AI into software development: on one hand, the fast integration of modern LLMs into products – and on the other, data privacy, compliance, auditability, and clear responsibilities.
In practice, three operating models for AI workloads have emerged:
- Public API
- Cloud in the company’s own tenant
- On-premise
These three approaches differ in their levels of data protection, scalability, and integration effort, but can be combined into a hybrid, secure enterprise AI architecture through API gateways and agent orchestration.
Public API – Speed and Innovation
Public APIs offer the fastest entry point into generative AI. Within just a few hours, you can set up chatbots, assistants, or analysis tools – ideal for non-sensitive data.
Advantages of a Public API
- Extremely short time-to-value
- Immediate access to new model capabilities
- Scaling and costs initially handled by the provider
Limitations of a Public API
- Limited data sovereignty
- Lack of auditability
- Not suitable for sensitive information
Typical use cases: Prototyping, content generation, data exploration, publicly available information
Cloud in Your Own Tenant – Scalability and Integration
Operating in the cloud expands the pure model invocation into a complete enterprise workload. In addition to elastic compute capacity (including GPUs), the cloud offers a broad AI ecosystem: identity and access management (RBAC), CI/CD, observability, vector databases, and specialized services like OCR, speech-to-text, vision, or AI Foundry offerings.
Advantages of Cloud in Your Own Tenant
- Integrated governance and compliance
- Standardized deployment via Infrastructure as Code (IaC)
- EU-compliant data residency (depending on the provider)
Challenges of Cloud in Your Own Tenant
- Provider lock-in due to IAM or storage APIs
- FinOps management required for continuous workloads
Typical use cases: Productive internal AI workflows, retrieval-augmented generation (RAG), business process automation
On-Premise – Maximum Control and Data Sovereignty
On-premise operation offers complete control over data, infrastructure, and model versions – a must for highly regulated industries or sensitive data.
Advantages of On-Premise
- Highest data sovereignty and security
- Local optimization (e.g., quantization, distillation)
- Auditability at the stack level
Disadvantages of On-Premise
- High operational and maintenance effort
- Lack of cloud services (e.g., OCR, ASR, guardrails) – while this can be mitigated with the right expertise and significant effort, it is far from easy
- Economically viable only with consistently high utilization
Typical use cases: Regulatory domains, finance/healthcare, internal AI evaluation
Comparison of the Three AI Operating Models
| Criterion | Public API | Cloud (Own Tenant) | On-Premise |
| Time-to-Value | Very fast | Fast (IaC, automation) | Slow (setup required) |
| Data Sovereignty | Low | Medium to high | Maximum |
| Cost Model | Opex, low initial costs | Opex, elastic | CapEx + Opex, good with high utilization |
| Lock-in Risk | High | Medium (reducible via IaC) | Low (technical lock-in) |
| Governance & Audit | Limited | Integrated | Full |
| Use Cases | PoC, public data | Productive AI workflows | Highly sensitive areas |
API Gateway as the AI Integration Layer
The three paths are not mutually exclusive – in fact, an API or model gateway acts as a unified interface between applications and AI models. It ensures policy enforcement, logging, RBAC, rate limits, and routing decisions based on:
- Data classification
- Latency requirements
- Cost and sensitivity
This approach allows the same use case to run flexibly across Public API, Cloud, or On-Prem without the need for adjustments in the business applications.
Outcome: Clean audit trails, robust observability/FinOps metrics down to the route level, and technological independence.
Agent Orchestration – From Prompts to Processes
Agent orchestration transforms AI usage from individual prompts into scalable, reproducible business processes. In orchestration tools or equivalent internal pipelines, tasks (e.g., document input → OCR → classification → generation → review) are broken down into controllable steps and linked with checkpoints. Through the gateway, each step can be dynamically routed based on sensitivity, jurisdiction, and purpose.
Example:
Contract documents are first captured in an EU cloud service and parsed into structured sections using OCR and NLP. The subsequent extraction and evaluation of sensitive passages, such as personal data or clause variants, take place in the on-prem environment. Once the internal review is completed, the anonymized metadata is handed over to a cloud-based LLM, which generates a summary, risk assessment, or action recommendation. All processing steps are logged in the gateway, including routing decisions, model versions, and audit trails. Policies ensure that the original documents never leave the controlled zone. This enables sensitivity-aware routing and policy-compliant prompting across multiple environments.
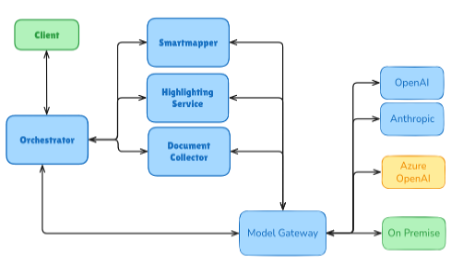
Integration into Enterprise AI Workflows
A typical flow begins with the orchestrator, which communicates quickly with the gateway, where policy checks, secrets management, and observability come into play. The routing logic then directs the request to the Public API, Cloud, or On-Prem. The response, costs, p95 latency, and decision path are centrally captured in the audit and observability stack.
For RAG (retrieval-augmented generation) scenarios, retrievers, vector databases, and context-building tools are added to the pipeline – either as a cloud service or on-prem within the company’s own stack. Through CI/CD and IaC, gateway configurations, prompts, models, and pipelines are version-controlled and deployed; canary comparisons between model variants allow for ongoing optimization of quality, cost, and latency.
Governance is built into the architecture from the start, not as an afterthought: policies, RBAC, PII protection, and audit mechanisms are integrated from day one.
Example:
An internal knowledge assistant processes support queries via the central API gateway. First, policy checks and secrets management are applied, after which the request is routed to a cloud instance with a RAG pipeline, based on its sensitivity. The retriever and vector database provide context-relevant documents, the LLM generates a response, and all metrics – including token consumption, p95 latency, and model routing – are logged in the observability stack. The gateway maintains the complete audit trail; configurations, prompts, and model versions are version-controlled and deployed via CI/CD pipelines. Policies and RBAC ensure that each step is traceable and compliant.
Conclusion: Hybrid Enterprise AI as the Key to Enterprise Maturity
- Public API offers maximum speed.
- Cloud scales production-ready with a broad AI ecosystem.
- On-Premise builds trust through maximum control.
The combination of these approaches through API gateways and agent orchestration allows for selecting the right level of data protection and performance depending on the use case and step. This creates a scalable, compliant, and provider-independent enterprise AI architecture.
FAQ: Enterprise-AI-Architectures – Public API, Cloud, and On-Prem
What are the three typical operational models for enterprise AI?
The three key operational models for enterprise AI are Public API, Cloud in your own tenant, and On-Premise. They primarily differ in terms of data privacy, governance, scalability, and cost structure. In practice, they are often combined in a hybrid approach to achieve the right balance of control and speed based on data classification or use case.
When is it useful to deploy a public API solution?
Public APIs are ideal for rapid experimentation and prototyping with generative AI. Companies can test new models or use cases within hours. However, data sovereignty is limited, so public APIs are only suitable for non-sensitive information or open datasets.
What advantages does a cloud instance in your own tenant offer?
A dedicated cloud tenant combines scalability with governance. Companies retain control over identities, policies, and data residency, while having access to managed AI services like vector databases, CI/CD, secrets management, and monitoring. This model is perfect for productive AI workflows and retrieval-augmented generation (RAG).
Why do regulated companies rely on on-prem AI?
On-prem solutions provide maximum data sovereignty and auditability, as all data, models, and logs remain within the company’s infrastructure. This is crucial for regulated industries like finance, government, or healthcare. The downside is higher maintenance effort and the loss of many cloud conveniences—however, this results in complete control and traceability.
What role does an API gateway play in AI architecture?
An API or model gateway serves as a central layer between applications and various AI backends. It manages routing, policy checks, secrets management, RBAC, and observability. This allows decisions to be made automatically about whether a request should go to a public API, cloud, or on-prem instance based on data classification or sensitivity—without requiring changes to applications. This improves governance, transparency, and cost control (FinOps).
What is agent orchestration in enterprise AI?
Agent orchestration refers to managing multi-step AI processes rather than individual prompts. A workflow might include document intake, classification, retrieval, generation, and verification. The gateway remains in the loop, monitors the process, enforces policies, and selects the appropriate backend. This creates traceable, reproducible enterprise AI flows instead of isolated model calls.
How is governance ensured in enterprise AI workflows?
Governance is integrated into the architecture, not an add-on. Policies, role-based access control (RBAC), PII protection, and audit trails are built into the gateway, orchestration, and CI/CD. Every model decision, latency, cost metric, or routing decision is logged in the observability stack. This ensures compliance-by-design, not post-hoc control.
What is a typical enterprise AI flow?
An enterprise AI workflow typically starts at the gateway:
– Policy checks and secrets handling
– Routing to cloud, on-prem, or API
– Measuring response time, costs, and model paths
– Storing in the audit stack
For RAG scenarios, retrievers, vector databases, and context building are added. Deployments are versioned via CI/CD and Infrastructure as Code (IaC) to consistently manage models, prompts, and pipelines.
How can quality, cost, and latency be continuously optimized?
Canary comparisons are used to test model versions or gateway configurations in parallel. Metrics like token usage, p95 latency, and response quality are fed into the central monitoring system. Based on this, quality, performance, and costs can be continuously balanced—an essential part of the FinOps framework for enterprise AI.
Why is a hybrid architecture often the best choice?
A hybrid enterprise AI architecture combines the flexibility of the cloud, the speed of public APIs, and the security of on-premise solutions. Through gateways and orchestration, it can dynamically decide where data should be processed for each step. This creates a scalable, compliant, and provider-independent AI landscape that blends speed and governance.




